Refreshable Materialized View (experimental)
Refreshable materialized views can be considered conceptually similar to materialized views in traditional OLTP databases, storing the result of a specified query for quick retrieval and reducing the need to repeatedly execute resource-intensive queries. Unlike ClickHouse’s incremental materialized views, this requires the periodic execution of the query over the full dataset - the results of which are stored in a target table for querying. This result set should in theory be smaller than the original dataset, allowing the subsequent query to execute faster.
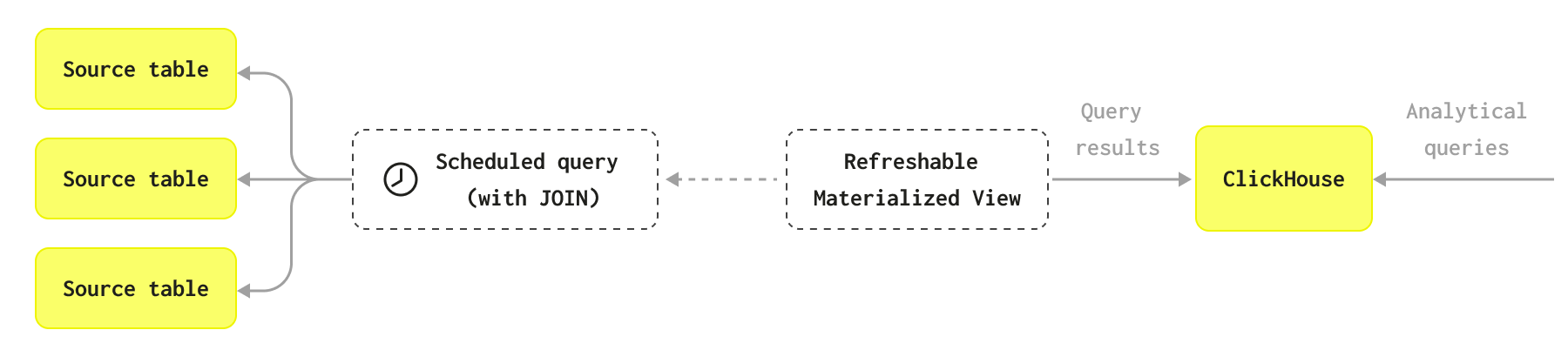
When should refreshable materialized views be used?
ClickHouse incremental materialized views are enormously powerful and typically scale much better than the approach used by refreshable materalized views, especially in cases where an aggregate over a single table needs to be performed. By only computing the aggregation over each block of data as it is inserted, and merging the incremental states in the final table, the query only ever executes on a subset of the data. This method scales to potentially petabytes of data and is usually the preferred method.
However, there are use cases where this incremental process is not required or is not applicable. Some problems are either incompatible with an incremental approach or don't require real-time updates, with a periodic rebuild being more appropriate. For example, you may want to regularly perform a complete recomputation of a view over the full dataset because it uses a complex join, which is incompatible with an incremental approach.
Refreshable materialized views can be used to run batch processes performing tasks such as denormalization. Dependencies can be created between refreshable materialized views such that one view depends on the results of another and only executes once it is complete. This can be used to replace scheduled workflows or simple DAGs such as a dbt job.
Example
As an example, consider the following query to denormalize the postlinks dataset onto the posts table for the StackOverflow dataset. We explored the reasons why users may wish to do this in our Denormalizing Data guide.
SELECT
posts.*,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Linked' AND p.2 != 0, Related)) AS LinkedPosts,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Duplicate' AND p.2 != 0, Related)) AS DuplicatePosts
FROM posts
LEFT JOIN (
SELECT
PostId,
groupArray((CreationDate, RelatedPostId, LinkTypeId)) AS Related
FROM postlinks
GROUP BY PostId
) AS postlinks ON posts_types_codecs_ordered.Id = postlinks.PostId
Both the posts and postlinks table could potentially be updated. Rather than attempt to implement this join using incremental materialized views, it may be sufficient to simply schedule this query to run at a set interval e.g. once every hour, storing the results in a post_with_links table.
Our syntax here is identical to an incremental materialized view except we include a REFRESH clause:
--enable experimental feature
SET allow_experimental_refreshable_materialized_view = 1
CREATE MATERIALIZED VIEW posts_with_links_mv
REFRESH EVERY 1 HOUR TO posts_with_links AS
SELECT
posts.*,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Linked' AND p.2 != 0, Related)) AS LinkedPosts,
arrayMap(p -> (p.1, p.2), arrayFilter(p -> p.3 = 'Duplicate' AND p.2 != 0, Related)) AS DuplicatePosts
FROM posts
LEFT JOIN (
SELECT
PostId,
groupArray((CreationDate, RelatedPostId, LinkTypeId)) AS Related
FROM postlinks
GROUP BY PostId
) AS postlinks ON posts_types_codecs_ordered.Id = postlinks.PostId
The view will execute immediately and every hour thereafter as configured to ensure updates to the source table are reflected. Importantly, when the query re-runs, the result set is atomically and transparently updated.