Using JOINs in ClickHouse
ClickHouse has full JOIN support, with a wide selection of join algorithms. To maximize performance, we recommend following the join optimization suggestions listed in this guide.
- For optimal performance, users should aim to reduce the number of
JOINs in queries, especially for real-time analytical workloads where millsecond performance is required. Aim for a maximum of 3 to 4 joins in a query. We detail a number of changes to minimize joins in the data modeling section, including denormalization, dictionaries, and materialized views. - Currently, ClickHouse does not reorder joins. Always ensure the smallest table is on the right-hand side of the Join. This will be held in memory for most join algorithms and will ensure the lowest memory overhead for the query.
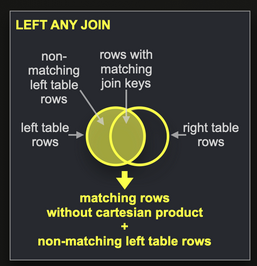
- If your query requires a direct join i.e. a
LEFT ANY JOIN- as shown below, we recommend using Dictionaries where possible.
- If performing inner joins, it is often more optimal to write these as sub-queries using the
INclause. Consider the following queries, which are functionally equivalent. Both find the number ofpoststhat don't mention ClickHouse in the question but do in thecomments.
SELECT count()
FROM stackoverflow.posts AS p
ANY INNER `JOIN` stackoverflow.comments AS c ON p.Id = c.PostId
WHERE (p.Title != '') AND (p.Title NOT ILIKE '%clickhouse%') AND (p.Body NOT ILIKE '%clickhouse%') AND (c.Text ILIKE '%clickhouse%')
┌─count()─┐
│ 86 │
└─────────┘
1 row in set. Elapsed: 8.209 sec. Processed 150.20 million rows, 56.05 GB (18.30 million rows/s., 6.83 GB/s.)
Peak memory usage: 1.23 GiB.
Note we use an ANY INNER JOIN vs. just an INNER join as we don't want the cartesian product i.e. we want only one match for each post.
This join can be rewritten using a subquery, improving performance significantly:
SELECT count()
FROM stackoverflow.posts
WHERE (Title != '') AND (Title NOT ILIKE '%clickhouse%') AND (Body NOT ILIKE '%clickhouse%') AND (Id IN (
SELECT PostId
FROM stackoverflow.comments
WHERE Text ILIKE '%clickhouse%'
))
┌─count()─┐
│ 86 │
└─────────┘
1 row in set. Elapsed: 2.284 sec. Processed 150.20 million rows, 16.61 GB (65.76 million rows/s., 7.27 GB/s.)
Peak memory usage: 323.52 MiB.
Although ClickHouse makes attempts to push down conditions to all join clauses and subqueries, we recommend users always manually apply conditions to all sub-clauses where possible - thus minimizing the size of the data to JOIN. Consider the following example below, where we want to compute the number of upvotes for Java-related posts since 2020.
A naive query, with the larger table on the left side, completes in 56s:
SELECT countIf(VoteTypeId = 2) AS upvotes
FROM stackoverflow.posts AS p
INNER JOIN stackoverflow.votes AS v ON p.Id = v.PostId
WHERE has(arrayFilter(t -> (t != ''), splitByChar('|', p.Tags)), 'java') AND (p.CreationDate >= '2020-01-01')
┌─upvotes─┐
│ 261915 │
└─────────┘
1 row in set. Elapsed: 56.642 sec. Processed 252.30 million rows, 1.62 GB (4.45 million rows/s., 28.60 MB/s.)
Re-ordering this join improves performance dramatically to 1.5s:
SELECT countIf(VoteTypeId = 2) AS upvotes
FROM stackoverflow.votes AS v
INNER JOIN stackoverflow.posts AS p ON v.PostId = p.Id
WHERE has(arrayFilter(t -> (t != ''), splitByChar('|', p.Tags)), 'java') AND (p.CreationDate >= '2020-01-01')
┌─upvotes─┐
│ 261915 │
└─────────┘
1 row in set. Elapsed: 1.519 sec. Processed 252.30 million rows, 1.62 GB (166.06 million rows/s., 1.07 GB/s.)
Adding a filter to the right side table improves performance even further to 0.5s.
SELECT countIf(VoteTypeId = 2) AS upvotes
FROM stackoverflow.votes AS v
INNER JOIN stackoverflow.posts AS p ON v.PostId = p.Id
WHERE has(arrayFilter(t -> (t != ''), splitByChar('|', p.Tags)), 'java') AND (p.CreationDate >= '2020-01-01') AND (v.CreationDate >= '2020-01-01')
┌─upvotes─┐
│ 261915 │
└─────────┘
1 row in set. Elapsed: 0.597 sec. Processed 81.14 million rows, 1.31 GB (135.82 million rows/s., 2.19 GB/s.)
Peak memory usage: 249.42 MiB.
This query can be improved even more by moving the INNER JOIN to a subquery, as noted earlier, maintaining the filter on both the outer and inner queries.
SELECT count() AS upvotes
FROM stackoverflow.votes
WHERE (VoteTypeId = 2) AND (PostId IN (
SELECT Id
FROM stackoverflow.posts
WHERE (CreationDate >= '2020-01-01') AND has(arrayFilter(t -> (t != ''), splitByChar('|', Tags)), 'java')
))
┌─upvotes─┐
│ 261915 │
└─────────┘
1 row in set. Elapsed: 0.383 sec. Processed 99.64 million rows, 804.55 MB (259.85 million rows/s., 2.10 GB/s.)
Peak memory usage: 250.66 MiB.
Choosing a join algorithm
ClickHouse supports a number of join algorithms. These algorithms typically trade memory usage for performance. The following provides an overview of the ClickHouse join algorithms based on their relative memory consumption and execution time:
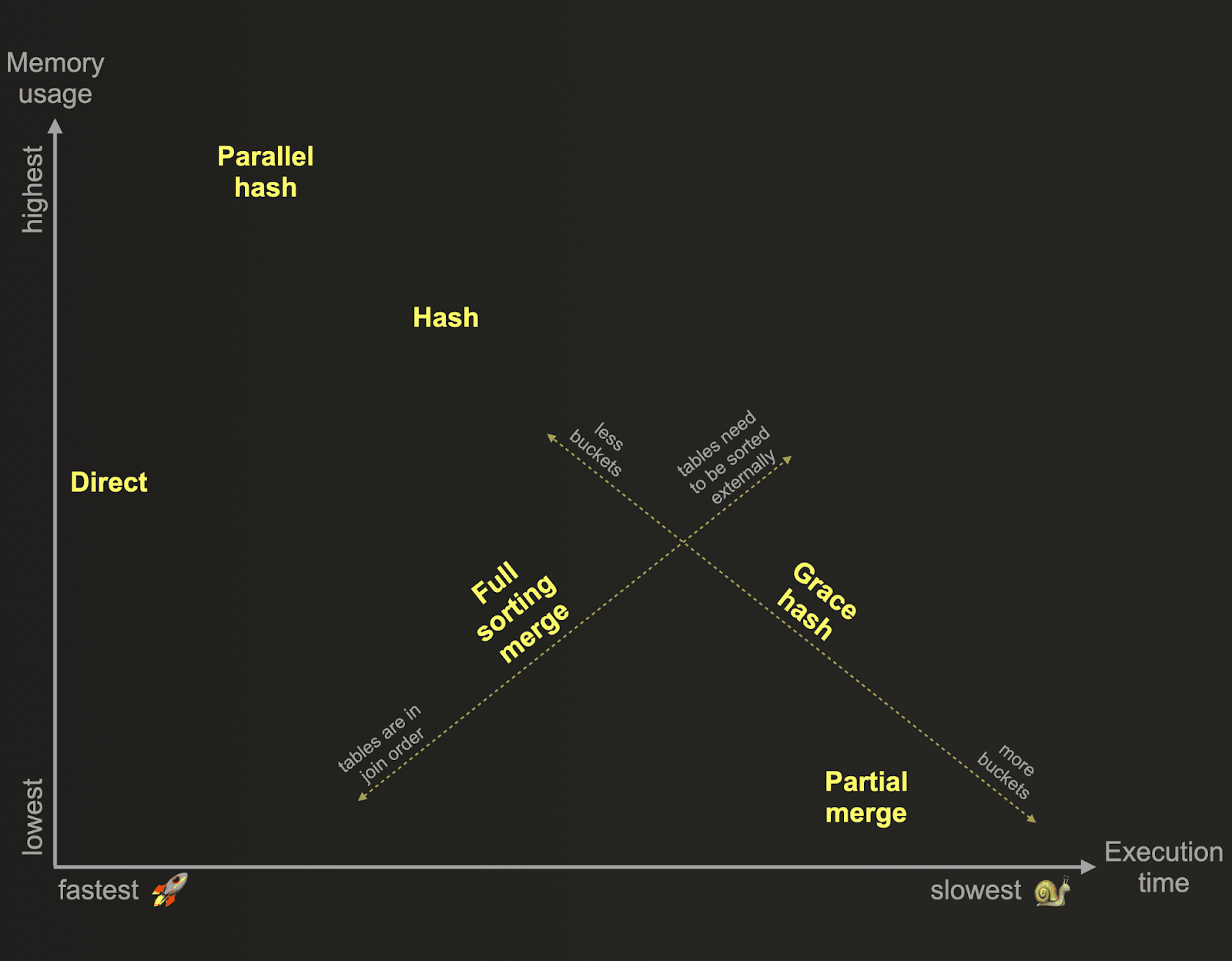
These algorithms dictate the manner in which a join query is planned and executed. By default, ClickHouse uses the direct or the hash join algorithm based on the used join type and strictness and engine of the joined tables. Alternatively, ClickHouse can be configured to adaptively choose and dynamically change the join algorithm to use at runtime, depending on resource availability and usage: When join_algorithm=auto, ClickHouse tries the hash join algorithm first, and if that algorithm's memory limit is violated, the algorithm is switched on the fly to partial merge join. You can observe which algorithm was chosen via trace logging. ClickHouse also allows users to specify the desired join algorithm themselves via the join_algorithm setting.
The supported JOIN types for each join algorithm are shown below and should be considered prior to optimization:
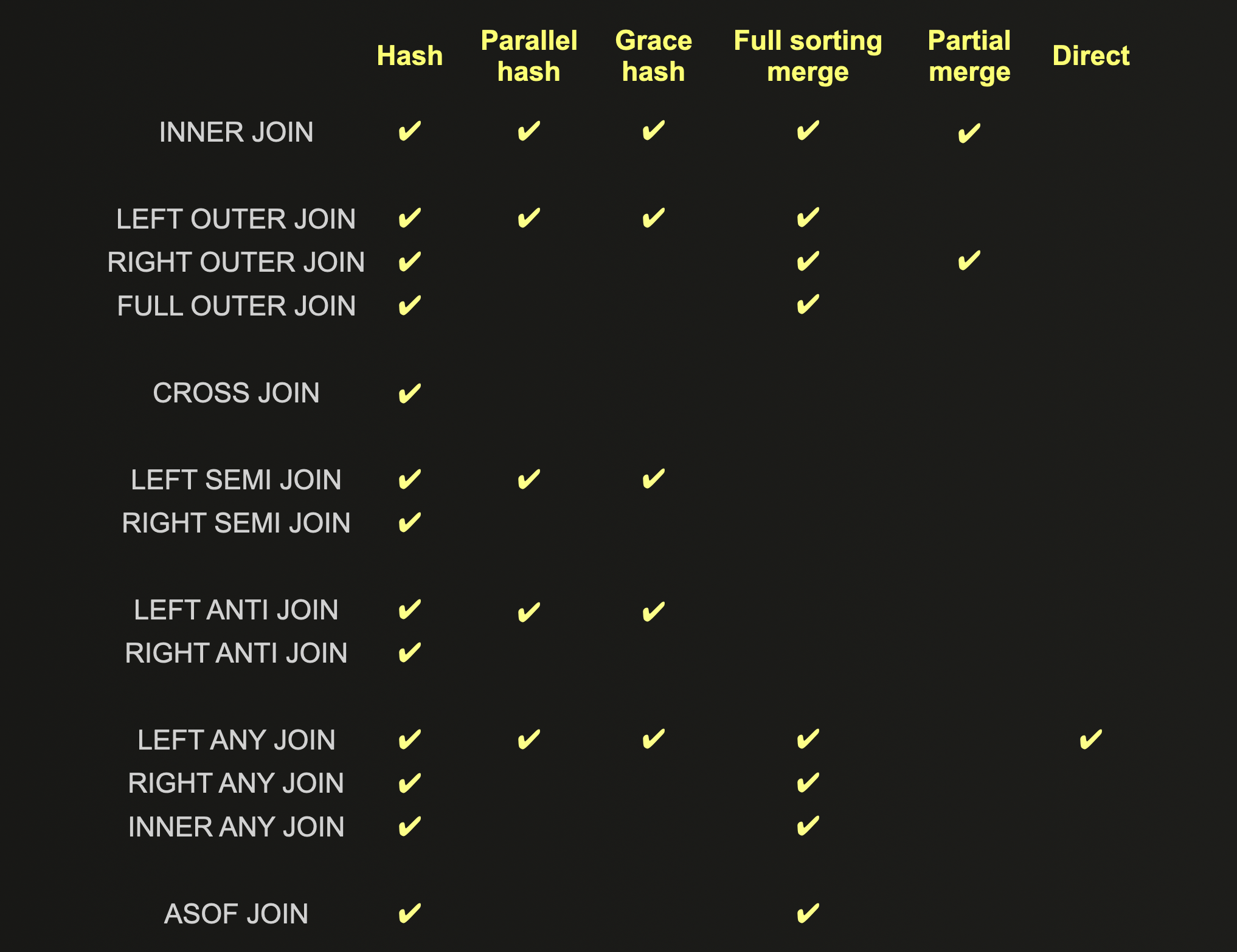
A full detailed description of each JOIN algorithm can be found here, including their pros, cons, and scaling properties.
Selecting the appropriate join algorithms depends on whether you are looking to optimize for memory or performance.
Optimizing JOIN performance
If your key optimization metric is performance and you are looking to execute the join as fast as possible, you can use the following decision tree for choosing the right join algorithm:
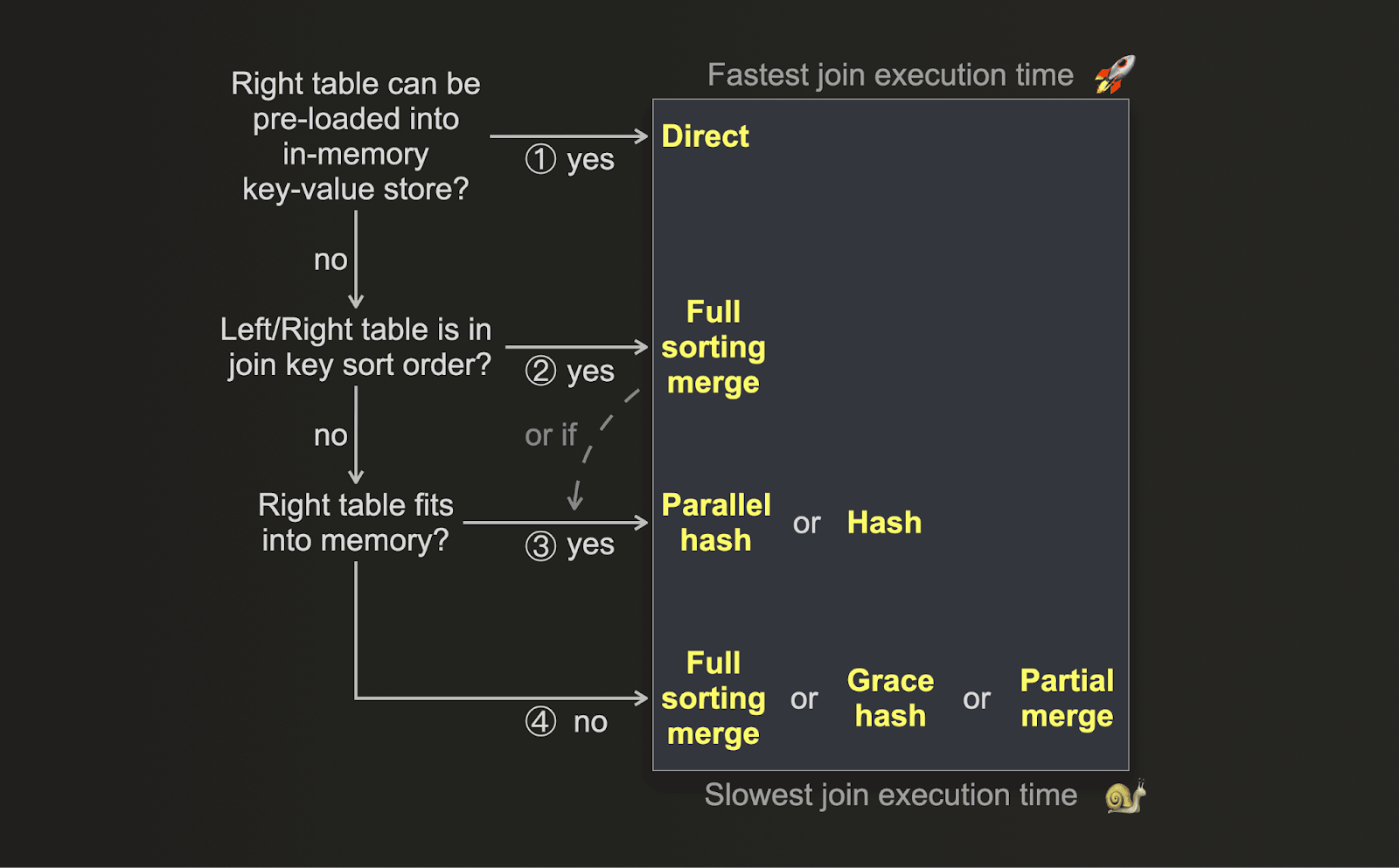
(1) If the data from the right-hand side table can be pre-loaded into an in-memory low-latency key-value data structure, e.g. a dictionary, and if the join key matches the key attribute of the underlying key-value storage, and if
LEFT ANY JOINsemantics are adequate - then the direct join is applicable and offers the fastest approach.(2) If your table's physical row order matches the join key sort order, then it depends. In this case, the full sorting merge join skips the sorting phase resulting in significantly reduced memory usage plus, depending on data size and join key value distribution, faster execution times than some of the hash join algorithms.
(3) If the right table fits into memory, even with the additional memory usage overhead of the parallel hash join, then this algorithm or the hash join can be faster. This depends on data size, data types, and value distribution of the join key columns.
(4) If the right table doesn't fit into memory, then it depends again. ClickHouse offers three non-memory bound join algorithms. All three temporarily spill data to disk. Full sorting merge join and partial merge join require prior sorting of the data. Grace hash join is building hash tables from the data instead. Based on the volume of data, the data types and the value distribution of the join key columns, there can be scenarios where building hash tables from the data is faster than sorting the data. And vice versa.
Partial merge join is optimized for minimizing memory usage when large tables are joined, at the expense of join speed which is quite slow. This is especially the case when the physical row order of the left table doesn't match the join key sorting order.
Grace hash join is the most flexible of the three non-memory-bound join algorithms and offers good control of memory usage vs. join speed with its grace_hash_join_initial_buckets setting. Depending on the data volume the grace hash can be faster or slower than the partial merge algorithm, when the amount of buckets is chosen such that the memory usage of both algorithms is approximately aligned. When the memory usage of grace hash join is configured to be approximately aligned with the memory usage of full sorting merge, then full sorting merge was always faster in our test runs.
Which one of the three non-memory-bound algorithms is the fastest depends on the volume of data, the data types, and the value distribution of the join key columns. It is always best to run some benchmarks with realistic data volumes of realistic data in order to determine which algorithm is the fastest.
Optimizing for memory
If you want to optimize a join for the lowest memory usage instead of the fastest execution time, then you can use this decision tree instead:
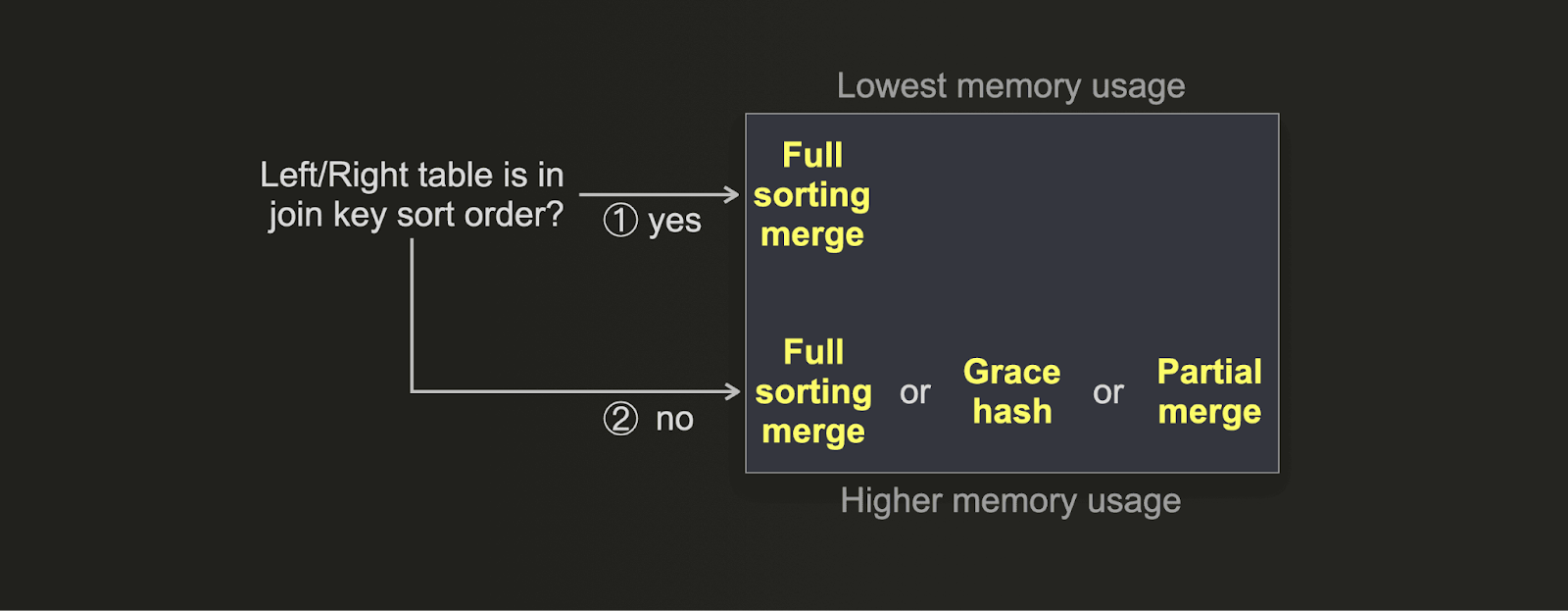
- (1) If your table's physical row order matches the join key sort order, then the memory usage of the full sorting merge join is as low as it gets. With the additional benefit of good join speed because the sorting phase is disabled.
- (2) The grace hash join can be tuned for very low memory usage by configuring a high number of buckets at the expense of join speed. The partial merge join intentionally uses a low amount of main memory. The full sorting merge join with external sorting enabled generally uses more memory than the partial merge join (assuming the row order does not match the key sort order), with the benefit of significantly better join execution time.
For users needing more details on the above, we recommend the following blog series.